1. Schematische Darstellung des Verfahrens random forest
Zusätzlich haben wir im Training sogenannte Hyperparameter über eine maximale Entropiematrix anhand eines extending horizon (time series split in der cross validation mit zwölf folds) mit zunehmender Anzahl an Trainingsdaten nachjustiert. Dabei wurden folgende Hyperparameter variiert:
- die Anzahl zufällig ausgewählter Variablen (mtry) für decision trees (dt),
- die Anzahl der zu berechnenden dt (trees) sowie
- die Anzahl der minimal vorhandenen Sample-Größe je split (min_n).
Die Optimierung wurde mithilfe des resultierenden F1-Scores durchgeführt. Da die Daten imbalanced waren (meistens gab es keine Veränderung im Abstimmungsverhalten), haben wir downsampling eingesetzt, bei dem randomisiert Beobachtungen aus der Mehrheitskategorie ausgeschlossen werden. Für die Analyse haben wir das R-Package tidymodels von Max Kuhn und Hadley Wickham genutzt.
Wir haben im Prozess verschiedene Modellspezifikationen ausgewählt, die sich in den folgenden Aspekten unterscheiden:
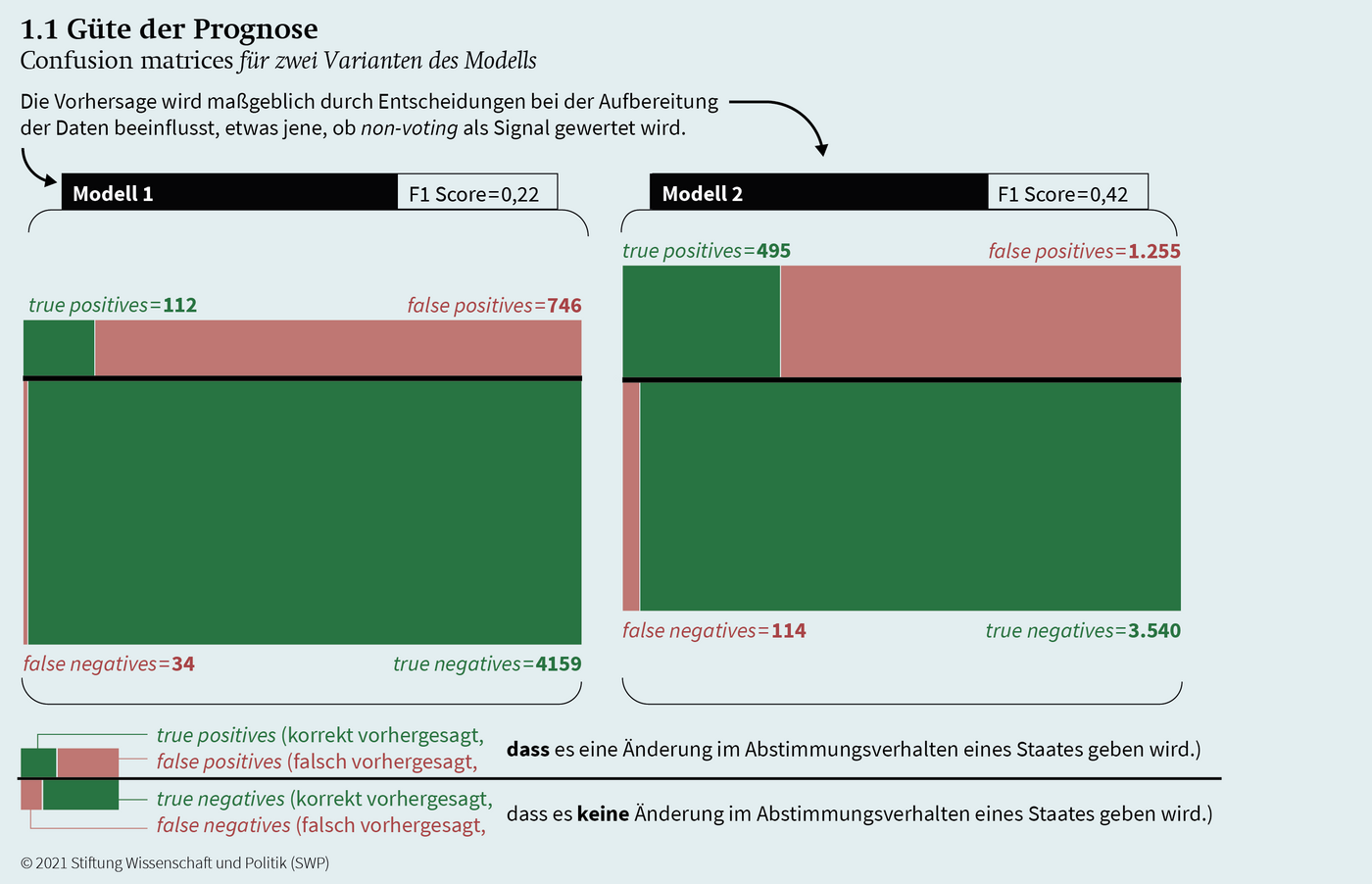
In der politischen Praxis sind die voraussichtlichen Positionen der fünf ständigen Mitglieder des VN-Sicherheitsrates (P5) meistens im Voraus bekannt. Deswegen wurden bei einigen Modellen die Positionen der P5 (und entsprechend ggf. deren Veränderungen) für die zu prognostizierenden Resolutionen bewusst mit berücksichtigt. Die These dahinter lautet, dass dies ein relevanter Datenpunkt für die Prognose des Verhaltens von anderen Staaten sein könnte. Diese Konfiguration wurde sowohl für Modell 1 als auch für Modell 2 in Abbildung 1.1 gewählt.
In den VN gibt es vier Abstimmungspositionen: „Ja“, „Nein“, Enthaltung und Nicht-Teilnahme (non-voting). In einigen Modellen haben wir eine Veränderung des Abstimmungsverhaltens registriert, wenn ein Staat an einer Abstimmung nicht teilgenommen hat, bei anderen Modellen haben wir dieses Verhalten ausgeschlossen.
Als Beispiel:
-
Resolution A, Staat X, Session 70 = Ja
-
Resolution A, Staat X, Session 71 = non-voting
-
Resolution A, Staat X, Session 72 = Ja
In Modell 2 (s. Abbildung 1.1) sind hier zwei Änderungen registriert: Von „Ja“ zu non-voting und von non-voting zu „Ja“. In Modell 1 (s. Abbildung 1.1) ist hier keine Änderung enthalten, da die Position non-voting in Session 71 ausgeschlossen wird und von „Ja“ zu „Ja“ keine Änderung besteht.
Im Laufe des Projektes sind wir zu dem Ergebnis gekommen, dass für die diplomatische Praxis die sensitivity, d. h. die Rate der erkannten Veränderungen am wichtigsten ist. Dementsprechend haben wir in einer weiteren Modellspezifikation den threshold – also den Grad der Wahrscheinlichkeit, ab dem eine prognostizierte Veränderung tatsächlich als Veränderung gewertet wird (z. B. Wahrscheinlichkeit der Veränderung mindestens 60 %) – anhand der sensitivity maximiert (zwischen 0 und 1). Hierfür haben wir den Wert ausgesucht, mit dem mindestens 80 % der Veränderungen erfasst und die wenigsten Abstimmungsergebnisse falsch prognostiziert wurden. Streng genommen wurde demnach nicht nur nach sensitivity maximiert, sondern der beste F1-Score mit einer sensitivity von mindestens 80 % ausgewählt. Diese Methode wurde bei Modell 1 und 2 (Abbildung 1.1) angewandt.
Ergebnis und Güte der Prognose
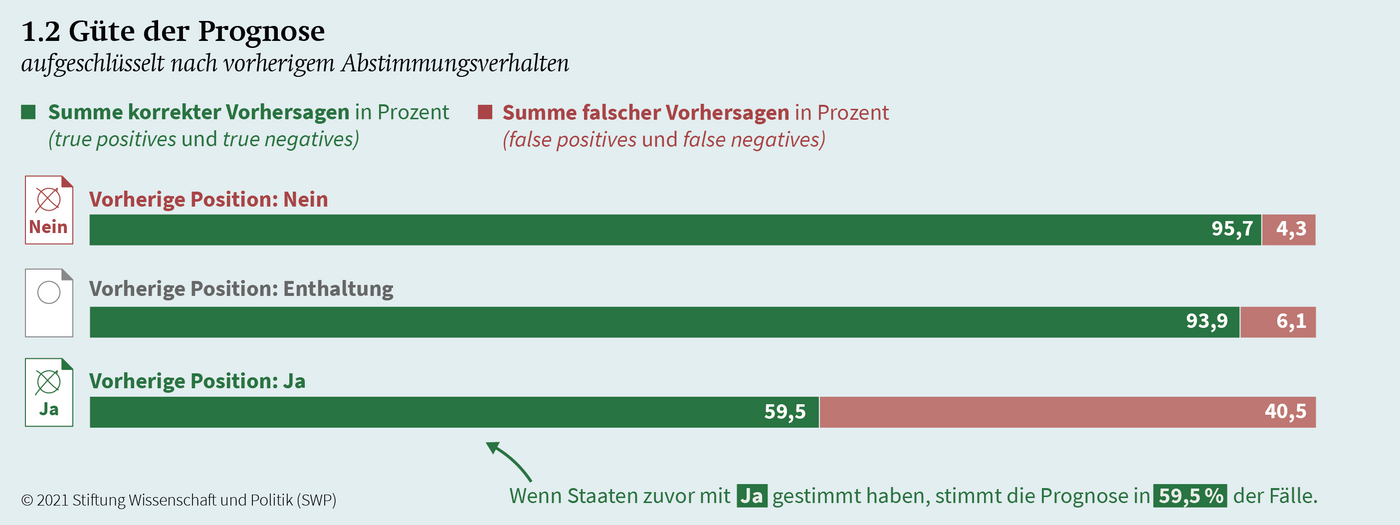
Das Ergebnis dieses Pilotprojektes lautet, dass eine solche Prognose grundsätzlich möglich ist, die Güte der Prognose allerdings bisher noch nicht gänzlich zufriedenstellt: Erfasst man einen Großteil der Veränderungen im Staatenverhalten, zahlt man dafür mit teils sehr vielen false positives. Auch scheint das Modell für unterschiedliche Staaten unterschiedlich gut zu funktionieren, wobei hier bis jetzt noch keine klare Systematik zu erkennen ist. Durch weitere Arbeit an dem Modell und ggf. Hinzufügen weiterer Daten scheint es uns aber möglich, die Prognose weiter zu verbessern. In jedem Fall ist es ratsam, ein solches System so zu gestalten, dass das Erfahrungswissen aus der Praxis der Diplomaten integriert werden kann.
Die folgenden Abbildungen fassen unsere Ergebnisse bzgl. der Güte der Prognose zusammen: